A few months ago, I took on the responsibility of managing a non-relational DocumentDB database, which has since been updated to CosmosDB, hosted on Azure. During this journey, I encountered challenges, particularly when it came to deleting specific records. It became evident that understanding how partitions work and selecting the correct partition by ID played a pivotal role in overcoming these obstacles.
To facilitate this process, I developed a Windows console application sample in C#. This application serves to collect document IDs based on a query and subsequently deletes the documents associated with those IDs. This tool has proven to be invaluable in efficiently managing and maintaining our database, streamlining the deletion process for optimal database performance.
Initially we install the libraries Microsoft.Azure.DocumentDB and Newtonsoft.Json.
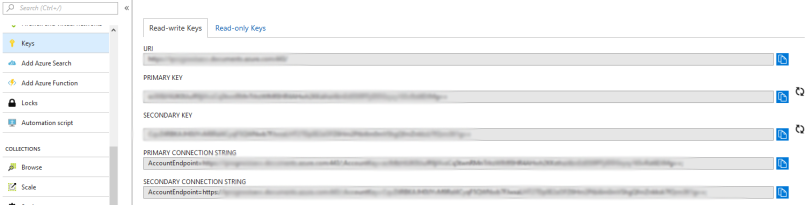
To establish a connection between the DocumentDB database and the Windows console application, you will require the necessary credentials, including the URI and primary key. These credentials can be found in the “keys” tab within the Azure portal.
Next, you’ll need to initialize the DocumentDB URI, primary key, as well as specify the collection and database names.
private const string connectionEndpointUri ="https://dropdocuments.documents.azure.com:443/"; private const string primaryKey = "Kl9XbLDeSPjcmoJra7tKkHblfamvhmxFdzcw7LN3Pl44ENCdBYHax6krgmqGgqfpRbUEj73Rml0YAOR2ALJBZg=="; private static string databaseId = @"DatabaseName"; private static string collectionId = @"CollectionName"; private Uri collectionLink = UriFactory.CreateDocumentCollectionUri(databaseId, collectionId);
Additionally, initialize the DocumentClient, which serves as a client-side representation for the Azure DocumentDB service.
private static DocumentClient client;
For this tutorial, our goal is to retrieve all the keys, and to do so, we will execute the query “SELECT f.id FROM f.” It’s crucial to specify the partition. If you haven’t defined a partition in your DocumentDB database, you can use the value “Undefined.Value” in the FeedOptions for the partitionKey field. However, if you have a defined partition, use the name of the partition key that exists in your database.
List<string> documentIds = await CollectIdsAsync();
public async static Task<List<string>> CollectIdsAsync()
{
List<string> documentIds = new List<string>();
FeedOptions feedOptions = new FeedOptions();
feedOptions.PartitionKey = new PartitionKey("yourpartitionkey");
using (client = new DocumentClient(new Uri(connectionEndpointUri), primaryKey))
{
Uri collectionLink = UriFactory.CreateDocumentCollectionUri(databaseId, collectionId);
var query = client.CreateDocumentQuery(collectionLink, "Select f.id From f", feedOptions).AsDocumentQuery();
while (query.HasMoreResults)
foreach (var item in await query.ExecuteNextAsync())
documentIds.Add(Convert.ToString((object)item));
}
return documentIds;
}
Once you’ve gathered the document IDs, you’ll need to delete these documents from the Azure DocumentDB.
client = null;
public class ResponseID
{
public string id { get; set; }
}
foreach (string id in documentIds)
await DeleteDocumentAsync(JsonConvert.DeserializeObject<ResponseID>(id).id);
public static async Task DeleteDocumentAsync(string id)
{
Document doc = GetDocument(id);
RequestOptions requestOptions = new RequestOptions();
requestOptions.PartitionKey = new PartitionKey("yourpartitionkey");
await Client.DeleteDocumentAsync(doc.SelfLink, requestOptions);
}
private static DocumentClient Client
{
get
{
if (client == null)
{
string endpoint = connectionEndpointUri;
string authKey = primaryKey;
Uri endpointUri = new Uri(endpoint);
client = new DocumentClient(endpointUri, authKey);
}
return client;
}
}
private static Document GetDocument(string id) { FeedOptions feedOptions = new FeedOptions(); feedOptions.PartitionKey = new PartitionKey("yourpartitionkey"); return Client.CreateDocumentQuery(UriFactory.CreateDocumentCollectionUri(databaseId, collectionId), feedOptions) .Where(d => d.Id == id) .AsEnumerable() .FirstOrDefault(); }
You can find this sample code and download it from GitHub using the following link: https://github.com/gntakakis/AzureDocumentDBDropDocuments.
